The Element of Financial Econometrics
1. Chapter 5 The Efficient Portfolios and CAPM
1.1. With Risk-free asset
Optimize allocation factor using Markowitz's mean-variance optimization, which is equivalent to optimize the expected utility under exponential utility. Notice that the risk-free asset here can be used to eliminate the constraint of weights sum to one.
For any optimal solutions, they have the same Sharpe ratio, therefore the efficient frontier is a line with slope=optimal Sharpe ratio and intercept the risk-free rate.
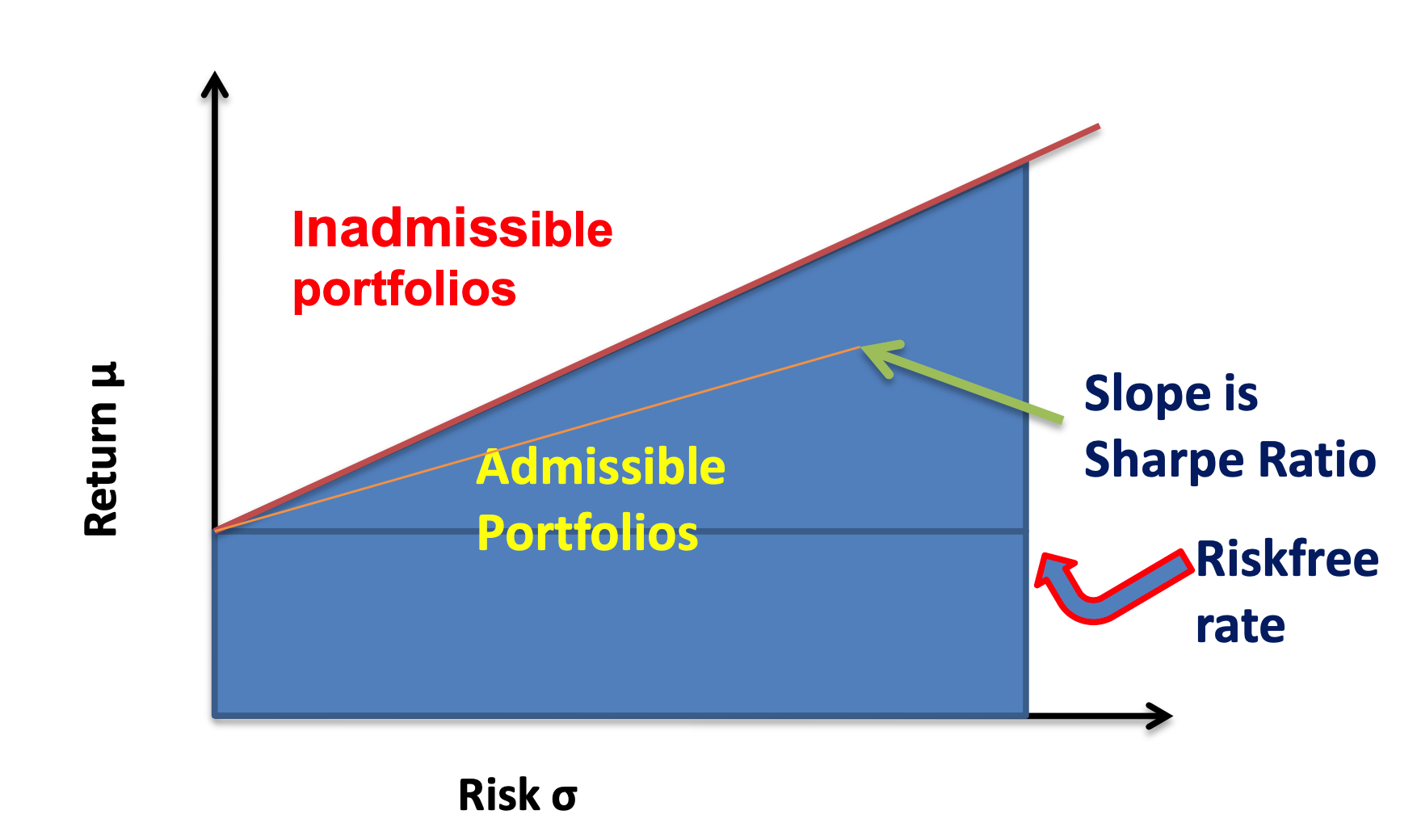
It can be shown that the market portfolio (with market value-weighted allocation vector) is on the efficient frontier and by two fund separation theorem, any efficient portfolio can be decomposed into the market portfolio and the risk-free one.
CAPM: For the excess return of any portfolio, denote as the excess return of market portfolio, we have
and is the external noise.
The CAPM model can be validated using
- Econometrics: regression and hypothesis testing
- Maximum likelihood estimation with Wald test or likelihood ratio test.
1.2. Without Risk-free asset
We need to solve a constraint version of Markowitz's mean-variance optimization problem. It is also not hard using Lagrangian. This time, the efficient frontier is a parabola.
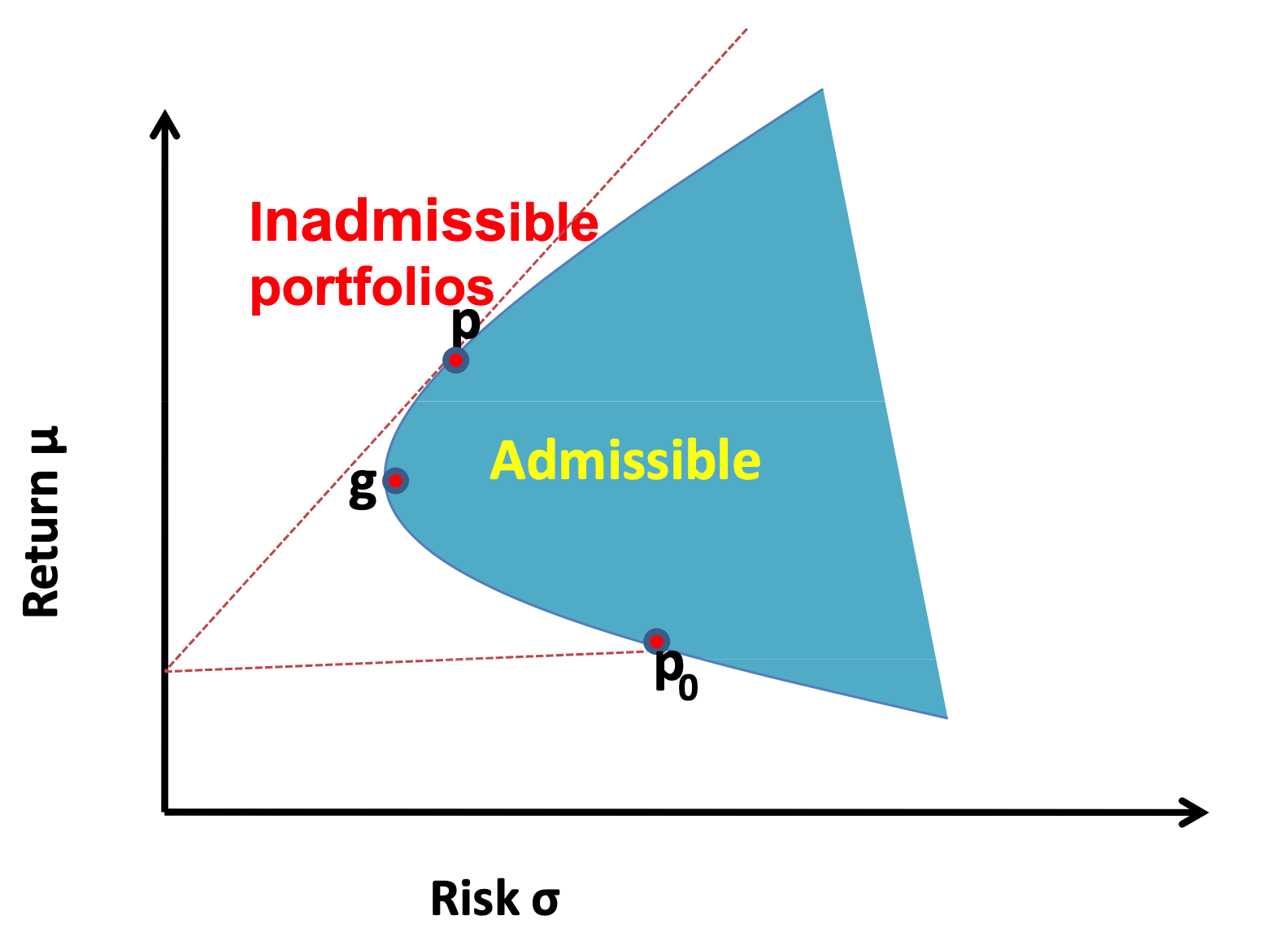
For any portfolio on the frontier, you can find another one on the frontier that has zero beta with the previous one. The CAPM model is similarly formulated using one portfolio (as market portfolio) and its excess return is compared using its zero-beta counterparts (as risk-free one).
2. Chapter 6 Factor Pricing Models
2.1. Multi-factor models
The multi-factor model with return , factor loading matrix , factor and external noise ,
The multi-factor pricing model with expected return , risk-free return ,
where is the excess return of factors. Using multi-factor pricing model, we can estimate the covariance matrix of return with fewer parameters:
Notice that multi-factor model is always valid since this is a statistical decomposition (P245) but multi-factor pricing model needs to be validated.
2.2. Validate multi-factor pricing model
If there is a risk-free asset, the multi-factor pricing model can be formed as
where is the excess return of all asset and the hypothesis test is simply,
If there is not a risk-free asset, we need to compare multi-factor model with multi-factor pricing model and the hypothesis test is,
Both test can be done using a likelihood ratio test where (and in the risk-free absence case) can be estimated using maximum likelihood estimation iteratively if we assume the residual has a normal distribution.
If we use macroeconomic factors, whose excess return cannot be observed, we can estimate using MLE and change the hypothesis test accordingly.
2.3. PCA and factor analysis
For the multi-factor pricing model, if we assume the residual covariance matrix is identity matrix, then it can be shown that the solution of MLE is the same as PCA results. and the first principal component of sample covariance matrix of return span the same subspace.
When the portfolio size is large, the PCA and factor analysis are approximately the same. See Fan, Liao and Mincheva (2013).
3. Chapter 7 Portfolio Allocation and Risk Assessment
3.1. Risk approximation
For any portfolio allocation vector , we define the gross exposure of the portfolio as . Therefore,
The variance of this portfolio is
with estimated covariance matrix , the empirical risk is
For any portfolio with allocation vector ,
where .
Fan, Liao and Shi (2015) use the concept of high confidence level upper bound (H-CLUB),
3.2. Estimation of a large volatility matrix
Exponential Smoothing
Denote the conditional covariance matrix of return on time . The traditional way to estimate is using the return matrix from time to time and compute the sample covariance matrix as
If we consider to localize the data, one naive way is to define a window and
A better way is using Exponential Smoothing method, with a smoothing parameter ,
and the estimated volatility matrix can be computed recursively as
Thresholding regularization
When the portfolio size is large, to deal with the ill-conditioned problem in estimation of volatility matrix, we can use a thresholding method. Given our estimated matrix and a thresholding parameter ,
or using a adaptive thresholding estimator,
where is the estimated standard error of .
Projection onto positive definite matrix space
To make our estimated covariance matrix a valid covariance matrix after thresholding, we can use
or we can solve a optimization problem, for any symmetric matrix ,
Here is set to
and for the solution to the optimization problem , the corrected covariance matrix is
Regularization by penalized likelihood
Penalized likelihood is useful to explore the sparsity. Denote be the log-likelihood function, we assume is sparse and the penalized likelihood is
where is a penalty function. Usually we set , the penalty, which results in the best subset selection. However, it is computationally expensive. The LASSO estimator, which uses -penalty, is a convex relaxation but introduces biases due to the shrinkage of LASSO.
Fan and Li (2001) introduced a family of folded-concave penalty functions such as the smoothly clipped absolute deviation (SCAD) whose derivative is
The penalized likelihood with SCAD as penalty function can be solved by an iterated re-weighted LASSO using a local linear approximation (Zou and Li (2008)). For any estimate at , , the target is
where and
It can be shown that this algorithm is a majorization-minimization algorithm where the target value is decreasing with respect to sequence .
Estimate volatility matrix using factor model
Given factor model
We can run a regression to obtain and the regression residuals . And we can compute sample covariance matrix of . If we assume noise terms are independent of each other, we have the strict factor model based estimator,
This estimator has a better rate for estimating and the same rate for estimating compared to the sample covariance matrix of .
If instead we do not assume the uncorrelatedness of noise term, but explore the sparsity instead. We will have the following approximate factor model estimator,
where is the estimated error covariance matrix applied thresholding on correlation matrix with parameter .
Notice that if , then and if , is the sample covariance matrix of .
Now consider the approximate factor model with unobserved factors, we can use Principal Orthogonal complEment Thresholding (POET) by Fan, Liao and Mincheva (2013).
- Obtain the sample covariance matrix based on returns.
- Run a singular value decomposition: .
- Compute the residual covariance matrix .
- Regularize to obtain e.g. correlation matrix thresholding.
- Compute the POET estimator as
POET encompasses many methods, when , it is sample covariance matrix; when , it is strict factor model with unknown factors; when , it is thresholded sample covariance matrix.
High-dimensional PCA and factor analysis
The factor model
for any non-singular matrix . Therefore, we can assume and columns of are orthogonal. Therefore,
If the factors are strong (pervasive), then we have asymptotically,
and
where are the eigenvectors and eigenvalues of covariance matrix of .
3.3. Portfolio allocation with gross-exposure constraints
Our previous Markowitz’s mean-variance analysis is usually too sensitive on input vectors and their estimation errors and can result in extreme short positions. This problem is more severe for large portfolio.
We consider optimization with gross-exposure constraint:
Now if we only consider the risk profile not the return. We can define actual and perceived risks:
and oracle and empirical allocation vectors
Let . Then, we have,
Now we show the convergence rate of . If for a sufficiently large ,
for some positive constants a and and rate , then
Moreover, suppose that is bounded and that the returns are weakly dependent in that its mixing coefficient decays exponentially, namely for some . If , then we have the above convergence rate. (See Fan, Zhang and Yu (2012))
To better understand why the gross-exposure constraint helps on risk approximation, we make connections with covariance regularization. By the Lagrange multiplier method, our previous risk profile optimization is,
Let be the sub-gradient vector of the function , whose element is , or any values in depending on whether is positive, negative or zero, respectively. Then, the first order condition is
in addition to the constraints and . Let be the solution. We can show that it is also the solution to the unconstrained portfolio optimization problem
in which, with being the gradient evaluated at ,
We now show the link between regression and risk profile optimization. Set , we have
and the constraint on gross-exposure can be replaced by a similar norm.
4. Chapter 8 Consumption based CAPM
4.1. CCAPM
Representative consumer consumes on a representative good with quantity and price at time . His income consists of external income and shares on stocks with price . Now we have the budget constraint,
The Intertemporal choice problem: Let be the subjective dis- count factor. An individual wants to maximize w.r.t. the discounted expect utility, under the budget constraint
The first order condition for time is called Euler condition, with the stochastic discount factor
The same discount factor applies to price each asset:
The price depends on inflation rate , and intertemporal rate of substitution .
If there exists a risk-free asset with return , then
Notice that,
4.2. Power utility and normal distribution assumption
Assume the utility function has the following form:
where is the coefficient of relative risk aversion. Then,
Denote be the vector of the inflation-adjusted log-returns:
and assume follows a normal distribution, then we have the expected excess return (inflation-adjusted log return)
where .
4.3. Mean-variance frontier
Value of a portfolio: . Let . Then from CCAPM, and,
Therefore, we have
By the Cauchy-Schwartz inequality,
Efficient frontier: Excess gain (return) per unit risk (the Sharpe ratio) is bounded by , which is not always achievable. Because which is not tradable. If we can construct a stochastic discount factor using tradable portfolio, we can assure the efficient frontier can be achieved.
Consider where minimizes
The first order condition yields the Euler condition,
Therefore, we have and we can derive the above upper bound for Sharpe ratio again using ,
Obviously, attains the maximum Sharpe ratio, which is called the benchmark portfolio. And the excess gain for any portfolio can be expressed as
5. Chapter 9 Present-value Models
5.1. Fundamental price
The return of a stock using price and dividend,
Assume is a constant, then
Assume the growth condition
we have
This is the discounted dividend paid in the life time of a stock and it is called the discounted-cash-flow or present-value model.
If we assume dividends grow at a rate ,
Then the stock price is,
5.2. Rational bubbles
Recall the price equation,
with a unique solution
The general solution is where
Here is called fundamental value and is called rational bubble. The growth condition will rule out this possibility. The word "bubble" recalls some famous episodes in history in which asset price rose higher than could not easily be explained by fundamentals (investors betting other investors would drive prices even higher in the future). Notice that .
5.3. Time-varying expected returns
How to price an asset if the expected returns are not constant? Let average dividend-price ratio. The log-return , using Taylor’s expansion, we have the approximate present-value model
where and . By the condition that
we have the approximate pricing formula,