Reinforcement Learning: An Introduction (1)
1. Multi-armed Bandits
Denote the average reward for arm , the number of visits to arm .
-greedy algorithm

Upper-Confidence-Bound algorithm
Gradient bandit algorithms
2. Finite Markov Decision Processes
2.1. Notations
Denote as state, reward and actions at time .
discounted return:
state-value function:
action-value function:
optimal state-value function:
Optimal policies also share the same optimal action-value function:
2.2. Equations
Bellman equation for all :
relation between and :
Bellman optimality equation:
3. Dynamic Programming
The term dynamic programming (DP) refers to a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP). In Dynamic Programming, we know exactly what the model is, that is .
3.1. Policy Evaluation

3.2. Policy Improvement
Policy improvement theorem: Let and be any pair of deterministic policies such that, for all ,
then for all ,
Therefore, the new greedy policy is given by
If the new policy is just as good as the old one , then is the optimal policy (satisfies Bellman optimal equation):
3.3. Policy Iteration
Combine policy evaluation and policy improvement together, we have:

3.4. Value Iteration
One drawback to policy iteration is that each of its iterations involves policy evaluation, which may itself be a protracted iterative computation requiring multiple sweeps through the state set.
We can consider using policy evaluation where it stops after just one sweep (one update of each state). This algorithm is called value iteration.

4. Monte Carlo Methods
4.1. Monte Carlo Prediction

If a model is not available, then it is particularly useful to estimate action values (the values of state–action pairs) rather than state values. With a model (in DP case), state values alone are sufficient to determine a policy; one simply looks ahead one step and chooses whichever action leads to the best combination of reward and next state.
4.2. Monte Carlo Control
The algorithm is similar with DP case. However, we need to ensure all state-action pairs have a chance to be visited.

We can eliminate the exploring start assumption by using a -soft policy as follows:

It can be shown that
where the greater or equal is because the sum is a weighted average with nonnegative weights summing to , and as such it must be less than or equal to the largest number averaged.
By the policy improvement theorem is better than and equality can hold only when both and are optimal among the -soft policies, that is, when they are better than or equal to all other -soft policies.
4.3. Off-policy Prediction and Control via Importance Sampling
A more straightforward approach is to use two policies, one that is learned about and that becomes the optimal policy, and one that is more exploratory and is used to generate behavior. The policy being learned about is called the target policy, and the policy used to generate behavior is called the behavior policy. In this case we say that learning is from data off'' the target policy, and the overall process is termedoff''-policy learning.
Consider the target policy and the behavior policy , under , the state-action trajectory start from has the probability,
the relative probability of the trajectory under the target and behavior policies is
Therefore,
To estimate , we simply scale the returns by the ratios and average the results:
where would only include time steps that were first visits to s within their episodes.
The incremental implementation of off-policy Monte Carlo evaluation is shown below, where is the cumulative weights.

The corresponding off-policy MC control algorithm is as follows.

Notice that is taken as a greedy policy and only when it coincides with the path of policy $b$, the update will continue within a episode. Therefore, .
4.4. Optimize the Off-policy Importance Sampling
Define flat partial returns:
Therefore,
And the ordinary importance-sampling estimator and weighted importance-sampling estimator can be written as,
The essence of the idea is to think of discounting as determining a probability of termination or, equivalently, a degree of partial termination. Therefore, the variance of importance sampling can be reduced.
In the off-policy estimators, each term of the sum in the numerator is itself a sum:
where
We can show that,
Thus,
where
and the ordinary/weighted average of returns can be defined accordingly. This method, known as Per-decision Importance Sampling, is useful to reduce the variance of importance sampling.
5. Temporal-Difference Learning
5.1. TD(0) Learning: On-policy
We know that
TD(0) is a one-step bootstrap method which plug-in the current estimation of value function.

The TD(0) control algorithm (a.k.a. Sarsa) is

The convergence properties of the Sarsa algorithm depend on the nature of the policy’s dependence on Q. For example, one could use -greedy policies. Sarsa converges with probability to an optimal policy and action-value function as long as all state–action pairs are visited an infinite number of times and the policy converges in the limit to the greedy policy.
5.2. Q-learning: Off-policy TD Control
Notice that in TD(0) algorithm above, the step we take is based on current estimation of and the bootstrap method we used to update is also based on current estimation of . We can consider a off-policy control algorithm decouple the update from current estimation of .

We may also use expected value instead of maximum one:
5.3. Double-Q Learning
In Q-learning the target policy is the greedy policy given the current action values, which is defined with a max, and in Sarsa the policy is often -greedy, which also involves a maximization operation. In these algorithms, a maximum over estimated values is used implicitly as an estimate of the maximum value, which can lead to a significant positive bias.
We can consider using two policy together and update one and only one of them each time.

6. n-step Bootstrapping
6.1. n-step On-policy learning
The complete return is
In one-step updates the target is the first reward plus the discounted estimated value of the next state, which we call the one-step return:
Similarly, we can define n-step return as
The n-step return has a better prediction error than one-step return under worst case:

and the n-step Sarsa can be derived similarly.

6.2. n-step Off-policy Learning
Consider the target policy and the behavior policy . Define
Therefore, the off-policy n-step Sarsa is as follows.

6.3. Per-decision Methods with Control Variates
For the n steps ending at horizon , the n-step return can be written
with . All of the resulting experience, including the first reward and the next state must be weighted by the importance sampling ratio for time , . If is zero, a simple weighting would result in the n-step return being zero, which could result in high variance when it was used as a target. Instead, consider
If is zero, we just use current value to update (which causes no change), and since the expected value of is 1, this above update rule does not change the expected update.
For n-step expected Sarsa with the following rule:
we can write its corresponding control covariate method as
when , we use the off-policy expectation to make the update. And the expectation of is zero.
6.4. Off-policy Learning Without Importance Sampling: The n-step Tree Backup Algorithm
We consider a off-policy without importance sampling. In n-step off-policy Sarsa, we estimate using the reward from another policy . We now consider estimate this return with expected value over all actions except the action we take.
The one-step return (target) is the same as that of Expected Sarsa,
for and the two-step tree-backup return is
The latter form suggests the general recursive definition of the tree-backup n-step return:
This can be illustrated from the backup diagram below.
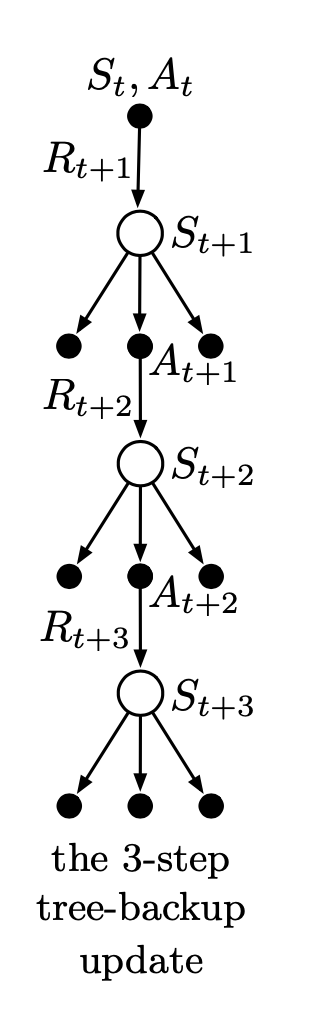
and the n-step tree-backup algorithm for control is:

6.5. A Unifying Algorithm
Consider unifying the importance sampling with tree-backup algorithm. First we write the tree-backup n-step return in terms of the horizon and then in terms of the expected approximate value ,
after which it is exactly like the n-step return for Sarsa with control variates except with the action probability substituted for the importance-sampling ratio . For , we slide linearly between these two cases:
