Reinforcement Learning: An Introduction (2)
1. On-policy Prediction with Approximation
1.1. Stochastic-gradient and Semi-gradient Methods for On-policy Approximation
Given a state distribution , we obtain a natural objective function, the Mean Squared Value Error, denoted :
Using stochastic gradient-descent (SGD),
Therefore, the SGD version for Monte Carlo state-value prediction algorithm is as follows.

If we use bootstrapping estimate of such as n-step TD, then this estimate relies on the current weights and the expression above is biased and will not produce true gradient descent. We call this kind of methods as semi-gradient methods.

1.2. Linear Methods
Denote as the feature vector for state . Linear methods approximate state-value function by the inner product between and :
Thus, in the linear case the general SGD update reduces to a particularly simple form:
The semi-gradient TD(0) algorithm presented in the previous section also converges under linear function approximation, but this does not follow from general results on SGD; a separate theorem is necessary. The weight vector converged to is also not the global optimum, but rather a point near the local optimum.
Once the system has reached steady state, for any given , the expected next weight vector can be written
where
if the system converges, it must converge to the weight vector which is called the TD fixed point. In fact linear semi-gradient TD(0) converges to this point.
At the TD fixed point, it has also been proven (in the continuing case) that the is within a bounded expansion of the lowest possible error:
The semi-gradient -step TD algorithm is the natural extension of the tabular -step TD algorithm presented to semi-gradient function approximation.

where the -step return is generalized as
1.3. Feature Construction for Linear Methods
Polynomials
Fourier Basis
Radial Basis Functions
Kernel-based Function
Coarse Coding:
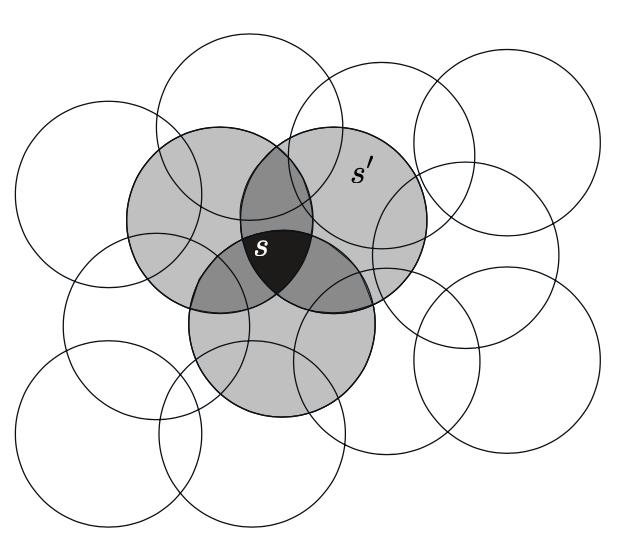
Consider a task in which the natural representation of the state set is a continuous two- dimensional space. One kind of representation for this case is made up of features corresponding to circles in state space, as shown to the right. If the state is inside a circle, then the corresponding feature has the value 1 and is said to be present; otherwise the feature is 0 and is said to be absent. This kind of -valued feature is called a binary feature. Given a state, which binary features are present indicate within which circles the state lies, and thus coarsely code for its location. Representing a state with features that overlap in this way (although they need not be circles or binary) is known as coarse coding.
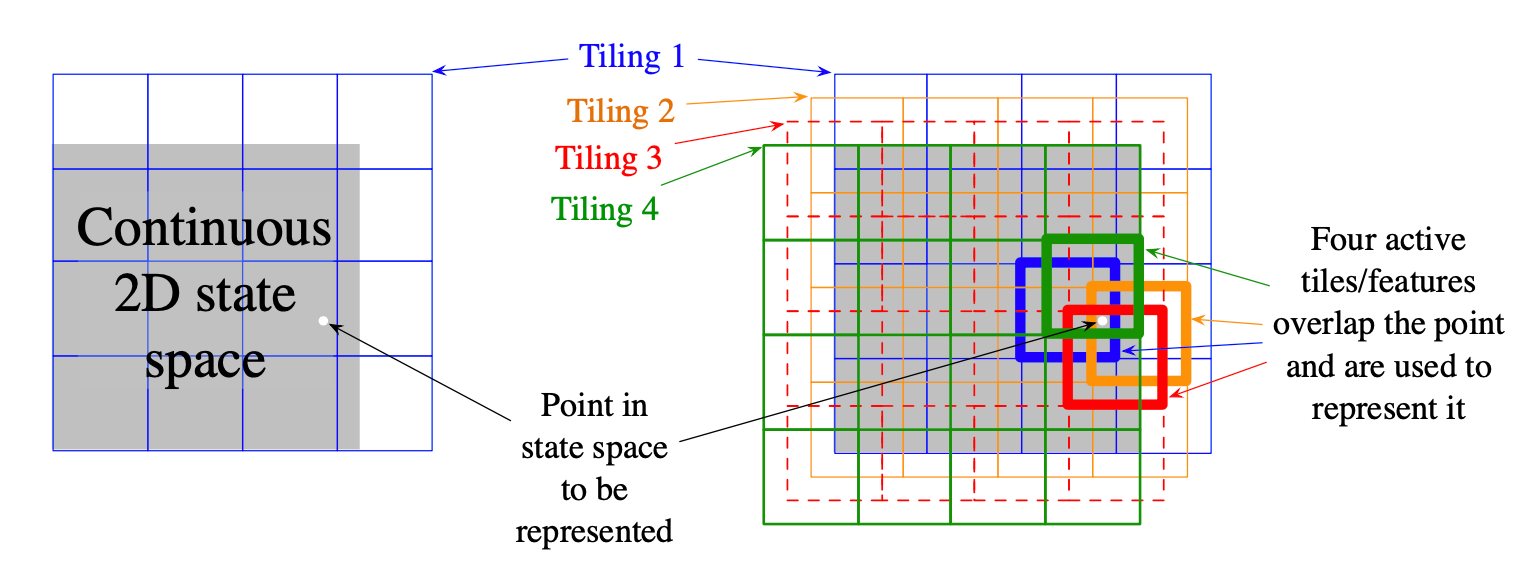
Tile Coding
Tile coding is a form of coarse coding for multi-dimensional continuous spaces that is flexible and computationally efficient. It may be the most practical feature representation for modern sequential digital computers. In tile coding the receptive fields of the features are grouped into partitions of the state space. Each such partition is called a tiling, and each element of the partition is called a tile.
1.4. Nonlinear Function Approximation: Artificial Neural Networks
1.5. Least-Squares TD
Recall TD fixed point
where
The Least-Squares TD algorithm, commonly known as LSTD, forms the natural estimates
where LSTD uses these estimates to estimate the TD fixed point as
In LSTD, the inverse of , and the computational complexity of a general inverse computation is . Fortunately, an inverse of a matrix of our special form - a sum of outer products - can also be updated incrementally with only computations, as
for , with . Although the identity known as the Sherman-Morrison formula, is superficially complicated, it involves only vector-matrix and vector-vector multiplications and thus is only . Thus we can store the inverse matrix maintain it and use it all with only memory and per-step computation. The complete algorithm is given below.

2. On-policy Control with Approximation
2.1. Episodic Semi-gradient Control
The update for the one-step Sarsa method is

We can obtain an -step version of episodic semi-gradient Sarsa by using an -step return as the update target in the semi-gradient one-step Sarsa update equation
where

2.2. Average Reward: A New Problem Setting for Continuing Tasks
In the average-reward setting, the quality of a policy is defined as the average rate of reward, or simply average reward, while following that policy, which we denote as :
where the expectations are conditioned on the initial state, , and on the subsequent actions, , being taken according to . is the steady-state distribution, , which is assumed to exist for any and to be independent of . This assumption about the MDP is known as ergodicity.
Note that the steady state distribution is the special distribution under which, if you select actions according to , you remain in the same distribution. That is, for which
In the average-reward setting, returns are defined in terms of differences between rewards and the average reward:
We simply remove all s and replace all rewards by the difference between the reward and the true average reward:

2.3. Differential Semi-gradient n-step Sarsa
We begin by generalizing the n-step return to its differential form, with function approximation:
where is an estimate of . Pseudocode for the complete algorithm is given in the box.

where
3. Off-policy Methods with Approximation
3.1. Semi-gradient Methods
The one-step, state-value algorithm is semi-gradient off-policy TD(0)
where is defined appropriately depending on whether the problem is episodic and discounted, or continuing and undiscounted using average reward:
For action values, the one-step algorithm is semi-gradient Expected Sarsa:
where
You can find the multi-step generalizations of these algorithms in a similar manner.
3.2. Examples of Off-policy Divergence
Consider estimating the state-value under the linear parameterization indicated by the expression shown in each state circle. For example, the estimated value of the leftmost state is , where the subscript corresponds to the component of the overall weight vector ; this corresponds to a feature vector for the first state being . The reward is zero on all transitions, so the true value function is , for all , which can be exactly approximated if . In fact, there are many solutions, as there are more components to the weight vector ( 8) than there are nonterminal states (7). Moreover, the set of feature vectors, , is a linearly independent set. In all these ways this task seems a favorable case for linear function approximation.
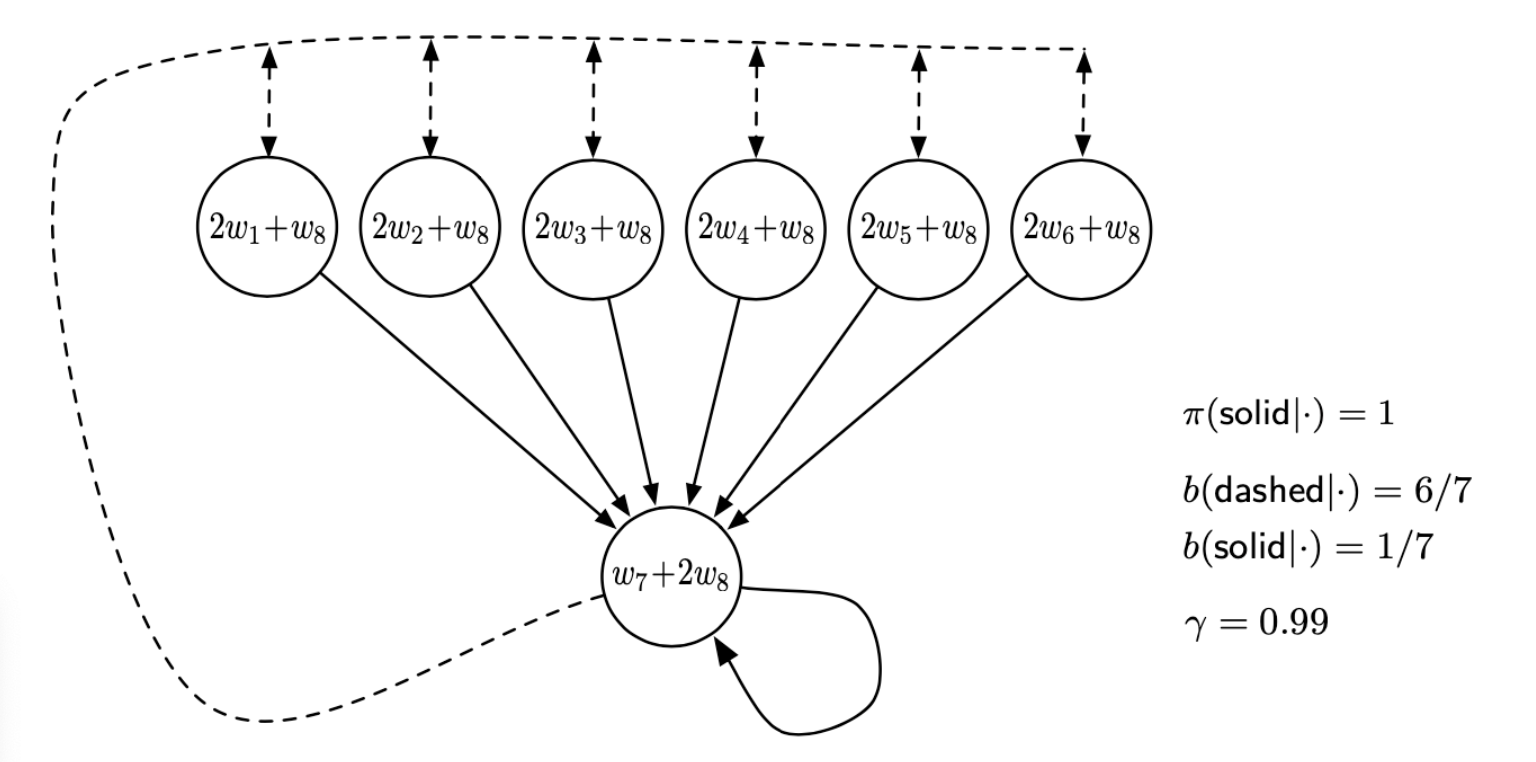
If we apply semi-gradient TD(0) to this problem, then the weights diverge to infinity. The instability occurs for any positive step size, no matter how small. In fact, it even occurs if an expected update is done as in dynamic programming (DP).
If we alter just the distribution of DP updates in Baird’s counterexample, from the uniform distribution to the on-policy distribution (which generally requires asynchronous updating), then convergence is guaranteed. The example shows that even the simplest combination of bootstrapping and function approximation can be unstable if the updates are not done according to the on-policy distribution.
There are also counterexamples similar to Baird’s showing divergence for Q-learning.
Our discussion so far can be summarized by saying that the danger of instability and divergence arises whenever we combine all of the following three elements, making up what we call the deadly triad:
Function approximation A powerful, scalable way of generalizing from a state space much larger than the memory and computational resources;
Bootstrapping Update targets that include existing estimates (as in dynamic programming or TD methods) rather than relying exclusively on actual rewards and complete returns (as in MC methods).
Off-policy training Training on a distribution of transitions other than that produced by the target policy. Sweeping through the state space and updating all states uniformly, as in dynamic programming, does not respect the target policy and is an example of off-policy training.
3.3. Linear Value-function Geometry
We can define the distance between value functions using the norm
Notice that we use for semi-gradient method is,
We define a projection operator that takes an arbitrary value function to the representable function that is closest in our norm:
For a linear function approximator, the projection operation is linear, which implies that it can be represented as an matrix:
where is the matrix with the diagonal element, and denotes the matrix whose rows are the feature vectors one for each state .
Recall the Bellman equation for value function, we define Bellman error at state ,
Therefore, the Mean Squared Bellman Error is,
The Bellman error vector is a result of applying the Bellman operator to the approximate value function. The Bellman operator is,
The Bellman error vector for can be written .
If the Bellman operator is applied to a value function in the representable subspace, then, in general, it will produce a new value function that is outside the subspace. In dynamic programming (without function approximation), this operator is applied repeatedly to the points outside the representable space. Eventually that process converges to the true value function , the only fixed point for the Bellman operator.
With function approximation, however, the intermediate value functions lying outside the subspace cannot be represented. In this case we are interested in the projection of the Bellman error vector back into the representable space. This is the projected Bellman error vector . Thus, we define the Mean Square Projected Bellman Error,
3.4. Gradient Descent in the Bellman Error
The one-step TD error with discounting is
Therefore,
This update and various ways of sampling it are referred to as the residual-gradient algorithm. If you simply used the sample values in all the expectations, the equation above involves the next state, , appearing in two expectations that are multiplied together. To get an unbiased sample of the product, two independent samples of the next state are required, but during normal interaction with an external environment only one is obtained. One expectation or the other can be sampled, but not both.
3.5. The Bellman Error is Not Learnable
In reinforcement learning, a hypothesis is said to be ``learnable'' if it can be learned with any amount of experience. It turns out many quantities of apparent interest in reinforcement learning cannot be learned even from an infinite amount of experiential data. These quantities are well defined and can be computed given knowledge of the internal structure of the environment, but cannot be computed or estimated from the observed sequence of feature vectors, actions, and rewards.
There are counterexamples where the optimal parameter vector of is not a function of the data and thus cannot be learned from it. However, another bootstrapping objective that we have considered, the , can be determined from data (are learnable) and determine optimal solution that is in general different from the $\overline{\mathrm{BE}}$ minimums.
3.6. Gradient-TD Methods
Remember that in the linear case there is always an exact solution, the TD fixed point , at which the is zero. This solution could be found by least-squares methods but only by methods of quadratic complexity in the number of parameters. We seek instead an SGD method.
The gradient with respect to is
To turn this into an SGD method, we have to sample something on every time step that has this quantity as its expected value. Notice that
and
Finally,
Substituting these expectations for the three factors in our expression,
Gradient-TD methods estimate and store the product of the second two factors above, denote as ,
This form is familiar to students of linear supervised learning. It is the solution to a linear least-squares problem that tries to approximate from the features. The standard SGD method for incrementally finding the vector that minimizes the expected squared error is known as the Least Mean Square (LMS) rule:
Therefore, the GTD2 algorithm is,
A slightly better algorithm can be derived by doing a few more analytic steps before substituting in , which is called GTD(0) algorithm:
4. Eligibility Traces
4.1. TD-lambda
Recall the n-step return,
Define the -return as,
we can separate these post-termination terms from the main sum, yielding
as indicated in the figures. This equation makes it clearer what happens when . In this case the main sum goes to zero, and the remaining term reduces to the conventional return. Thus, for , updating according to the -return is a Monte Carlo algorithm. On the other hand, if , then the -return reduces to , the one-step return.
We are now ready to define our first learning algorithm based on the -return: the offline -return algorithm. As an offline algorithm, it makes no changes to the weight vector during the episode. Then, at the end of the episode, a whole sequence of offline updates are made according to our usual semi-gradient rule, using the -return as the target:
TD() is one of the oldest and most widely used algorithms in reinforcement learning. TD () improves over the offline -return algorithm in three ways. First it updates the weight vector on every step of an episode rather than only at the end, and thus its estimates may be better sooner. Second, its computations are equally distributed in time rather than all at the end of the episode. And third, it can be applied to continuing problems rather than just to episodic problems. In this section we present the semi-gradient version of TD() with function approximation.
In the eligibility trace vector is initialized to zero at the beginning of the episode, is incremented on each time step by the value gradient, and then fades away by :
where is the discount rate and is the parameter introduced in the previous section, which we henceforth call the trace-decay parameter. The eligibility trace keeps track of which components of the weight vector have contributed, positively or negatively, to recent state valuations, where "recent" is defined in terms of .

We also show below the backward or mechanistic view of TD(). Each update depends on the current TD error combined with the current eligibility traces of past events.
Linear has been proved to converge in the on-policy case if the step-size parameter is reduced over time according to the usual conditions. For the continuing discounted case,
In practice, however, is often the poorest choice.
4.2. Online TD-lambda
In general, we define the truncated -return for time , given data only up to some later horizon, , as
The conceptual algorithm involves multiple passes over the episode, one at each horizon, each generating a different sequence of weight vectors. Let us use to denote the weights used to generate the value at time in the sequence up to horizon . The first weight vector in each sequence is that inherited from the previous episode.
The general form for the update is
Now we are ready to introduce the true online TD(). The sequence of weight vectors produced by the online -return algorithm can be arranged in a triangle:
One row of this triangle is produced on each time step. It turns out that the weight vectors on the diagonal, the , are the only ones really needed. The strategy then is to find a compact, efficient way of computing each from the one before. Pseudocode for the complete algorithm is given in the box.

We can define the action-value method (Sarsa()) similarly. The Sarsa() with binary features and linear function approximation is presented below.


4.3. Off-policy Traces with Control Variates
In the state case, we incorporate importance sampling with TD().
the truncated version of this return can be approximated simply in terms of sums of the state-based TD-error
and
Therefore,
The sum of the forward-view update over time is
which would be in the form of the sum of a backward-view TD update if the entire expression from the second sum left could be written and updated incrementally as an eligibility trace.
4.4. Eligibility Traces Q-learning
The concept of TB() is straightforward.
As per the usual pattern, it can also be written approximately as a sum of TD errors.
4.5. Stable Off-policy Methods with Traces
Several methods using eligibility traces have been proposed that achieve guarantees of stability under off-policy training, and here we present two of the most important ones.
GTD() is the eligibility-trace algorithm analogous to GTD(0) the better of the two state-value Gradient-TD prediction algorithms discussed above. Its goal is to learn a parameter such that , even from data that is due to following another policy . Its update is
where
GQ is the Gradient-TD algorithm for action values with eligibility traces. Its goal is to learn a parameter such that from off-policy. Its update is
where is the average feature vector for under the target policy, is the expectation form of the TD error,
HTD is a hybrid state-value algorithm combining aspects of GTD $(\lambda)$ and . Its most appealing feature is that it is a strict generalization of to off-policy learning, meaning that if the behavior policy happens to be the same as the target policy, then becomes the same as , which is not true for . HTD is defined as
5. Policy Gradient Methods
5.1. Policy Approximation and the Policy Gradient Theorem
In this chapter we consider methods for learning the policy parameter based on the gradient of some scalar performance measure with respect to the policy parameter. These methods seek to maximize performance, so their updates stochastic gradient ascent in is
In policy gradient methods, the policy can be parameterized in any way, as long as is differentiable with respect to its parameters.
If the action space is discrete and not too large, then a natural and common kind of parameterization is to form parameterized numerical preferences and the actions with the highest preferences in each state are given the highest probabilities of being selected. For example,
The action preferences themselves can be parameterized arbitrarily. For example, they might be computed by a deep artificial neural network, where is the vector of all the connection weights of the network. Or the preferences could simply be linear in features,
In the episodic case we define performance as
There is an excellent theoretical answer to this challenge in the form of the policy gradient theorem, which provides an analytic expression for the gradient of performance with respect to the policy parameter. The policy gradient theorem for the episodic case establishes that
The proof of the policy gradient theorem is given below.

5.2. REINFORCE: Monte Carlo Policy Gradient
Notice that
where we introduce and replace a sum over the random variable’s possible values by an expectation under , and then sampling the expectation.
Using this sample to instantiate our generic stochastic gradient ascent algorithm yields the REINFORCE update:
where is obtained by Monte-Carlo sampling.

5.3. REINFORCE with Baseline
The policy gradient theorem can be generalized to include a comparison of the action value to an arbitrary baseline :
since the baseline can be any function, even a random variable, as long as it does not vary with
The policy gradient theorem with baseline can be used to derive an update rule using similar steps as in the previous section. The update rule that we end up with is a new version of REINFORCE that includes a general baseline:
Because the baseline could be uniformly zero, this update is a strict generalization of REINFORCE. In general, the baseline leaves the expected value of the update unchanged, but it can have a large effect on its variance. For example, in the bandit algorithms the baseline was just a number (the average of the rewards seen so far), but for MDPs the baseline should vary with state. In some states all actions have high values and we need a high baseline to differentiate the higher valued actions from the less highly valued ones; in other states all actions will have low values and a low baseline is appropriate.
One natural choice for the baseline is an estimate of the state value, , where is a weight vector learned by one of the methods presented in previous chapters.
5.4. Actor–Critic Methods
Although the REINFORCE-with-baseline method learns both a policy and a state-value function, we do not consider it to be an actor–critic method because its state-value function is used only as a baseline, not as a critic. That is, it is not used for bootstrapping (updating the value estimate for a state from the estimated values of subsequent states), but only as a baseline for the state whose estimate is being updated. This is a useful distinction, for only through bootstrapping do we introduce bias and an asymptotic dependence on the quality of the function approximation. As we have seen, the bias introduced through bootstrapping and reliance on the state representation is often beneficial because it reduces variance and accelerates learning. REINFORCE with baseline is unbiased and will converge asymptotically to a local minimum, but like all Monte Carlo methods it tends to learn slowly (produce estimates of high variance) and to be inconvenient to implement online or for continuing problems. As we have seen earlier in this book, with temporal-difference methods we can eliminate these inconveniences, and through multi-step methods we can flexibly choose the degree of bootstrapping. In order to gain these advantages in the case of policy gradient methods we use actor–critic methods with a bootstrapping critic.
First consider one-step actor–critic methods. The main appeal of one-step methods is that they are fully online and incremental, yet avoid the complexities of eligibility traces.
The natural state-value-function learning method to pair with this is semi-gradient TD(0). The pseudocode is shown below.

The generalizations to the forward view of n-step methods and then to a -return algorithm are straightforward.

5.5. Policy Gradient for Continuing Problems
As discussed previously, for continuing problems without episode boundaries we need to define performance in terms of the average rate of reward per time step:
where is the steady-state distribution under which is assumed to exist and to be independent of (an ergodicity assumption).
Naturally, in the continuing case, we define values, and , with respect to the differential return:
With these alternate definitions, the policy gradient theorem as given for the episodic case remains true for the continuing case.