P-hacking
1. Introduction
2. Multiple Testing using Bootstrap
- Harvey, Campbell R., and Yan Liu. "Lucky factors." Journal of Financial Economics 141, no. 2 (2021): 413-435.
- 出色不如走运 II
基本思路:通过正交化和 Bootstrap 得到了仅靠运气能够得到的显著性的经验分布,再用empirical statistics 来跟经验分布比较。
2.1. Bootstrap on Panel Regression
Consider a time series regression model, where is the number of assets, and factor returns are long-short strategy returns corresponding to zero-cost investments.
考虑我们现在已经有了个factor如上式,增加一个新的factor 进入模型我们可以得到, 在null hypothesis下,新的factor对于解释asset在cross-section上的return没有任何帮助,因此应该有 . 我们考虑一个pseudo factor,, 为 在前面 张成的空间上的投影,即 在这种情况下,用原来的个因子和这个pseudo因子对asset return 做回归,得到的结果只会rescale , 而不会改变.
- This adjustment makes economic sense. The adjusted factor, , is absorbed by the pre-selected factors in the sense that its premium is completely explained by its exposure to the pre-selected factors. When this happens, the adjusted factor has a zero incremental impact on the cross-section of expected returns.
- In the meantime, it has perfect time series correlation with the original factor in sample and has the same time series correlation with the pre-selected variables as the original factor. Hence, the adjusted factor preserves the time series properties of the original factor aside from the mean.
这种情况下,通过构造pseudo factor , 我们得到了与原有factor 保持时间序列上correlation性质,但同时在sample下满足null hypothesis (新的factor对于解释asset在cross-section上的return没有任何帮助) 的因子。
我们通过在时间index上做bootstrap resample,并且重新做以下两个time series regression 并且通过 计算test statistic,并给出在null hypothesis 下的test statistic 经验分布,来得出原本用 计算的 test statistic 的p-value.
几种test statistic的计算方法如下:
- 最naive的
where is the standard deviation of .
- A robust version that calculates the percentage difference in the scaled median absolute intercept
- Value-weighted statistic
where is the time series of market equity for stock , and is the aggregate market equity at time .
We have several comments on the test statistics above:
- The use of the scaled intercept takes the heterogeneity in return volatilities into account.
- We scale the intercepts of the baseline model and the augmented model by the same standard error, that is, the standard error of the estimate of the intercept under the baseline model. This ensures that our test statistics are exactly zero when the null hypothesis, i.e., the candidate factor has zero incremental contribution to explain the cross-section of expected returns, is forced to exactly hold in sample for our procedure. This might not hold under alternative scaling schemes.
- For the first factor , we can subtract the in-sample mean of from its time series. In this way, we are projecting onto a vector of all ones.
2.2. Bootstrap for predictive regression
假设有因变量 Y 和 100 个解释变量 X 的 500 期样本数据,我们想看看哪个 X 能够预测 Y。多重检验的步骤为:
用每个 X 和 Y 回归(在我们的例子中就是 100 次回归),得到 100 个残差 OX,它们和 Y 正交。这构成了 null hypothesis:所有 OX 对 Y 没有预测性。
以这 500 期的 Y 和正交化得到的 OX 为原始数据(500 × 101 的矩阵,每一行代表一期,第一列为 Y,第二到第 101 列为 100 个 OX 变量),使用带放回的 Bootstrap 重采样从这 500 行中不断的随机抽取,构建和原始长度一样的 bootstrapped 数据(也是 500 × 101 矩阵)。整行抽取保留了这 100 个变量在截面上的相关性。此外 Bootstrap 的好处是不对原始数据中的概率分布做任何假设。
- 使用 bootstrapped 数据,用每个 OX 和 Y 回归得到一个检验统计量 (比如是 t-statistic); 找出所有 OX 中该检验统计量最大的那个值,称为 max statistic。如果我们的检验统计量是 t-statistic,那么这个 max statistic 就是 100 个 t-statistic 中最大的。
- 重复上述第二、第三步 10000 次,得到 max statistic 的经验分布(empirical distribution),这是纯靠运气(因为 null hypothesis 已经是 OX 对 Y 没有任何预测性了)能够得到的 max statistic 的分布。
- 比较原始数据 Y 和每个 X 回归得到的 max statistic 和第四步得到的 max statistic 的经验分布:
- 如果来自真实数据的 max statistic 超过了经验分布中的阈值(比如 95% 显著性水平对应的经验分布中 max statistic 的取值),那么真实数据中 max statistic 对应的解释变量就是真正显著的。假设这个解释变量是 X_7。
- 如果来自真实数据的 max statistic 没有超过经验分布中的阈值,则这 100 个解释变量全都是不显著的。本过程结束,无需继续进行。
- 使用目前为止已被挑出来的全部显著解释变量对 Y 进行正交化,得到残差 OY。它是原始 Y 中这些变量无法解释的部分。
- 使用 OY 来正交化剩余的 X(已经选出来显著变量,比如 X_7,不再参与余下的挑选过程)。
- 重复上述第三步到第七步:反复使用已挑出的显著因子来正交化 Y,再用 OY 来正交化剩余解释变量 X;在 Bootstrap 重采样时,使用 OY、k 个已经选出的 X、和剩余 100 - k 个正交化后的 OX 作为原始数据生成 bootstrapped 样本;通过大量的 Bootstrap 实验得到新的 max statistic 的经验分布,并判断剩余解释变量中是否仍然有显著的。
- 当剩余解释变量的 max statistic 无法超过 null hypothesis 下 max statistic 的经验分布阈值时,整个过程结束,剩余的解释变量全都是不显著的。
3. t-statistics Threshold using Multiple Testing
3.1. FWER and FDR control methods
A level- test for a single null hypothesis satisfies, by definition, For a collection of null hypotheses , the family-wise error rate (FWER) is the probability of making even one false rejection, Bonferroni's procedure controls FWER at level : let be the indices of the true , having say members. Then Bonferroni's procedure rejects all the with -value , the total number of hypothesis. Holm’s procedure offers modest improvement over Bonferroni, goes as follows,
Order the observed -values from smallest to largest,
Let be the smallest index such that
Reject all null hypotheses for and accept all with .
One can find a proof of Holm's procedure here: Holm–Bonferroni method proof
The false discovery proportion (FDP) is the proportion of type I errors: Here is the number of rejected null hypothesis and is the number of false discoveries. Therefore, the false discovery rate (FDR) is defined as Theoretically, FDR is always bounded above by FWER, to see this, Benjamini, Hochberg, and Yekutieli’s (BHY) adjustment provides a method that controls the FDR at level .
Order the observed -values from smallest to largest, and let the corresponding null hypotheses be
Let be the maximum index such that
Reject null hypotheses , but not .
The equivalent adjusted -value is defined sequentially as
3.2. Paper summary
t-statistics threshold
This paper studies many published factors using three adjustment methods previously introduced to the observed factor tests, under the assumption that the test results of all tried factors are available. They choose to set at (Bonferroni, Holm; FWER) and at (BHY; FDR) for the main results.
- For Bonferroni, the benchmark t-statistic starts at 1.96 and increases to 3.78 by 2012. It reaches 4.00 in 2032.
- Holm tracks Bonferroni closely and their differences are small.
- BHY implied benchmarks, on the other hand, are not monotonic. They fluctuate before year 2000 and stabilize at 3.39 (p- value = 0.007) after 2010. Intuitively, at any fixed significance level , the law of large numbers forces the false discovery rate (FDR) to converge to a constant.
- If we change the to for BHY, the corresponding BHY implied benchmark t-statistic is 2.78 (p-value = 0.0054) in 2012 and 2.81 (p-value = 0.0005) in 2032, still much higher than the starting value of 1.96.
Notice that the authors assume that the total number of tests equals the total number of discoveries. If there are any unpublished factors, they will only increase the t-statistics threshold. Therefore, the above t-statistics discussed only gives a lower bound.
Simulation with correlation structure
The authors also considers a simulation framework where the t-statistics for the -th factor portfolio follows a normal distribution, where in the prior distribution of mean is the distribution that has a point mass at zero.
They also incorporate cross-sectional correlations among contemporaneous returns. To overcome the missing data problem, they assume that their sample covers a fraction of t-statistics in between 1.96 and 2.57 and that all t-statistics above 2.57 are covered.
The quantities they choose to match and their values for the baseline sample are given by: The estimation works by seeking to find the set of parameters that minimizes the following objective function: Their simulation results is given in the table below.
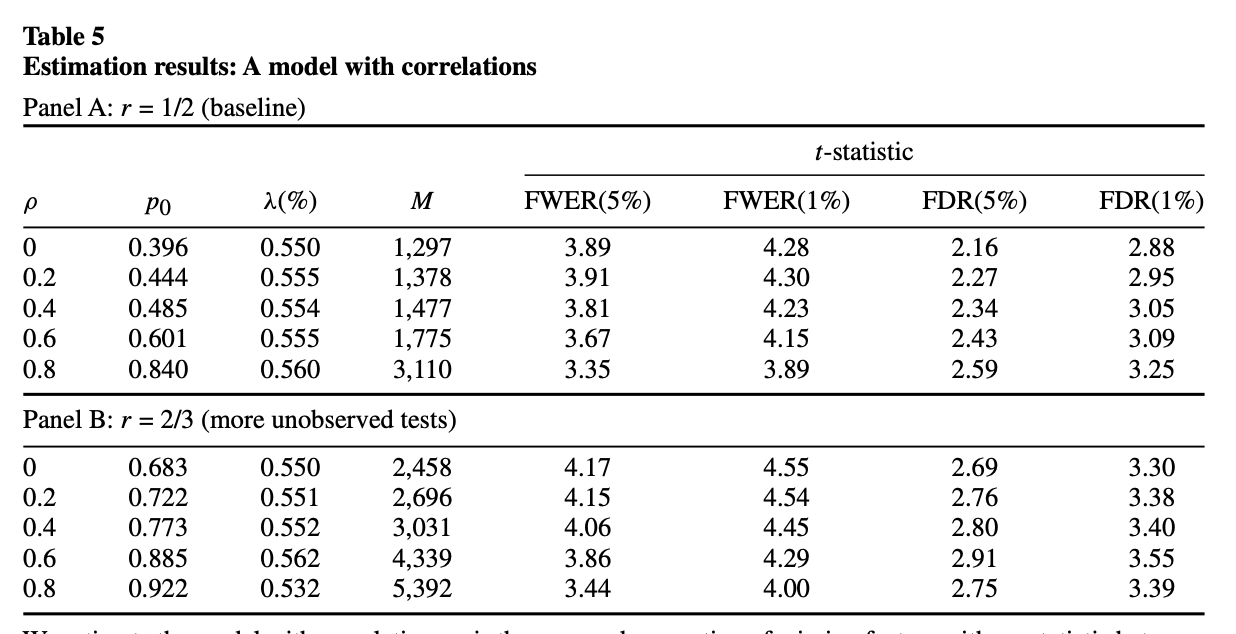
To conclude, a new factor needs to clear a much higher hurdle, with a t-statistic greater than 3.0.
4. Bayesian Approach
The MBF is the lower bound among all Bayes factors. It occurs when the density of the prior distribution of alternative hypotheses concentrates at the maximum likelihood estimate of the data.
The definition of Bayes factor is given by From the integral expression, the Bayes factor still depends on the prior specification of the alternative hypotheses (the density of under the alternative). However, we can define the minimum Bayes factor (MBF), which can bypass this problem and the MBF is the lower bound among all Bayes factors.
The MBF occurs when the density of the prior distribution of alternative hypotheses concentrates at the maximum likelihood estimate of the data. From the above definition and equivalences, we have Here is the maximum likelihood estimator under alternative.
Notice that by Bayes Theorem, the posterior probability is given by Here and are the prior of null and alternative hypothesis respectively. If we replace the Bayes factor by its lower bound, the minimum Bayes factor (MBF), we obtain an lower bound of the posterior probability,
5. Empirical Distribution of using Random Factors
6. t-statistics Threshold using Multiple Testing II
- Chordia, Tarun, Amit Goyal, and Alessio Saretto. "Anomalies and false rejections." The Review of Financial Studies 33, no. 5 (2020): 2134-2179.
- 出色不如走运 IV
A multiple testing procedure controls FDP at proportion and significance level if One way to control the FDP is the RSW method proposed by Romano and Wolf (2007) and Romano, Shaikh, and Wolf (2008). The RSW is meant to control the tail behavior of FDP, it avoids the concerns that controlling FDR exposes a researcher to the possibility that the realized FDP varies significantly across applications. 详细请看出色不如走运 IV全文。
7. The Existence of P-hacking
- Chen, Andrew Y. "The Limits of p‐Hacking: Some Thought Experiments." The Journal of Finance 76, no. 5 (2021): 2447-2480.
- Harvey, Campbell R., and Yan Liu. "Uncovering the iceberg from its tip: A model of publication bias and p-hacking." Available at SSRN 3865813 (2021).
- 出色不如走运 V
The core formula in Chen (2021) is the following lower bound: where is any -statistic threshold and is a standard normal random variable. Intuitively, if one makes hacking attempts, one should expect to find -statistics that exceed , (only a selected subset of the significant -statistics makes it into circulated working papers). 详细请看 出色不如走运 V 第二部分。
In both Chen (2021) and Harvey and Liu (2021), they define the shrinkage factor. Shrinkage is defined as the average percentage reduction of in-sample anomaly (absolute) return required to restore its population value. For example, an in-sample mean return of might be subject to a shrinkage of to restore its population mean return of .
Harvey and Liu (2021) 采用了类似于 Harvey and Liu (2020) False (and missed) discoveries in financial economics 一文中的double-bootstrap 方法,假设了bi-modal mean的data generating function,并且通过match target statistics来选择模型中的参数,详细请看 出色不如走运 V 第三部分。
8. Controlling the Type I and Type II Error using Double-bootstrap
- Harvey, Campbell R., and Yan Liu. "False (and missed) discoveries in financial economics." The Journal of Finance 75, no. 5 (2020): 2503-2553.
- 出色不如走运 (V)
基于双重 bootstrap 的多重假设检验框架,同时控制Type I 和 Type II errors. 对任意给定的, 我们control 的 Type I error,可以得到最优的Type II error 对应的t-statistics。详细请看出色不如走运 (V) 全文。