Latent Dirichlet Allocation
Python:
sklearn.decomposition.LatentDirichletAllocation.
1. Summary
This paper presents a generative probabilistic model for collections of discrete data such as text corpora. LDA is a three-level hierarchical Bayesian model with topics as latent variable. The parameter estimation and inference tasks can be made via a combination of variational method and EM algorithm.
2. Structure
We define:
- A word is the basic unit of discrete data, defined to be an item from a vocabulary indexed by . We encode words with one-hot coding.
- A document is a sequence of words denoted by , where is the th word in the sequence.
- A corpus is a collection of documents denoted by .
LDA assumes the following generative process for each document in a corpus :
- Choose .
- Choose . The dimension of this Dirichlet distribution is assumed known and fixed.
- For each of the words : (a) Choose a topic . (b) Choose a word from , a multinomial probability conditioned on the topic .
Basically, we allocate the multinomial probability of latent topics using hyper-parameter and then sample each word from the sampled multinomial distribution.
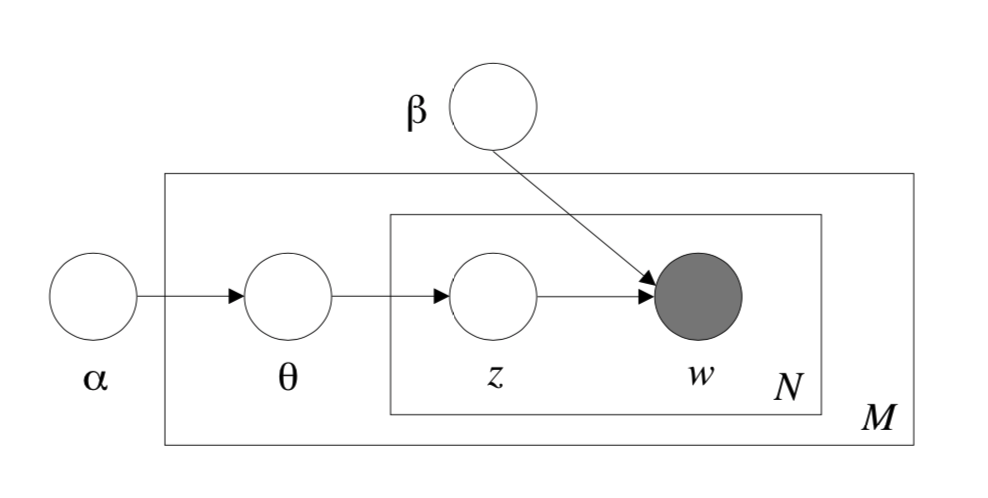 Figure 1: Graphical model representation of LDA. The boxes are "plates" representing replicates. The outer plate represents documents, while the inner plate represents the repeated choice of topics and words within a document.
Figure 1: Graphical model representation of LDA. The boxes are "plates" representing replicates. The outer plate represents documents, while the inner plate represents the repeated choice of topics and words within a document.
Therefore, we can obtain the marginal distribution of a document:
The probability of a corpus given parameter is
3. Learning and Inference
The key inferential problem that we need to solve in order to use LDA is that of computing the posterior distribution of the hidden variables given a document:
which is intractable because of the intractability of . We consider using a variational inference method to approximate this posterior distribution:
As for the learning task, we wish to find parameters and that maximize the (marginal) log likelihood of the data:
since is intractable, We can thus find approximate empirical Bayes estimates for the LDA model via an alternating variational EM procedure that maximizes a lower bound with respect to the variational parameters and , and then, for fixed values of the variational parameters, maximizes the lower bound with respect to the model parameters and :
- (E-step) For each document, find the optimizing values of the variational parameters . This minimization can be achieved via an iterative fixed-point method.
- (M-step) Maximize the resulting lower bound on the log likelihood with respect to the model parameters and . This corresponds to finding maximum likelihood estimates with expected sufficient statistics for each document under the approximate posterior which is computed in the E-step.