Relational Dependency Networks
1. Summary
Model the data using the idea of relational database and consider the autocorrelation between instances. The learning algorithm is novel, learning the CPDs based on the query that can return local sub-graphs. The learning algorithm can also produce dependency which interprets the relation between attributes. The inference process utilize the Gibbs sampler. However, it does not have the property like Markov network that the product of CPD is indeed the joint distribution, which is a trade-off between theoretical guarantee and cyclical network that describe wider connection between attributes.
2. Structure of the network
Instead of consider independent instance case, RDN consider there are dependency (autocorrelation) among instances and therefore construct a whole large graph connected all instances (by connecting their attributes).
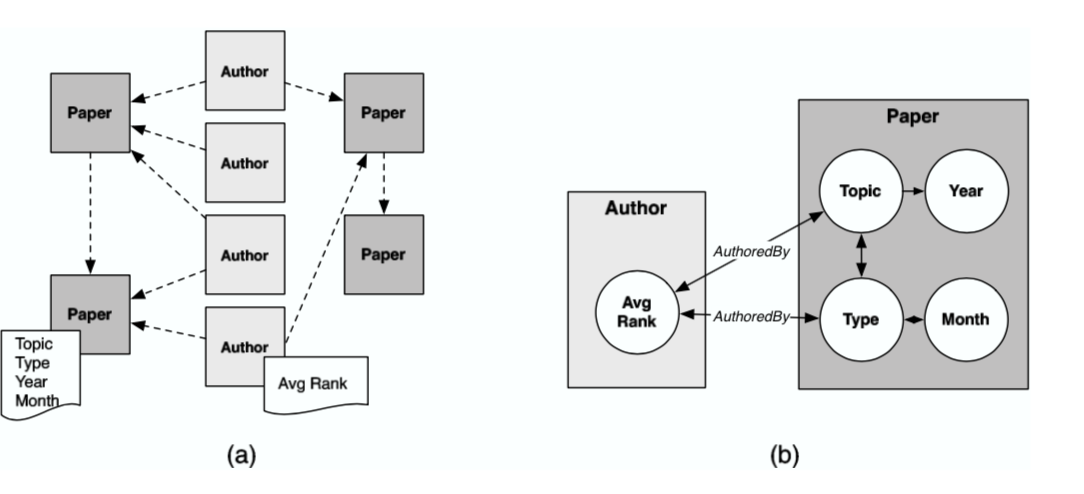
The relational data set is represented as a typed, attributed data graph . Consider the data graph in Figure 1(a). The nodes represent objects in the data (e.g., authors, papers) and the edges represent relations among the objects (e.g., author-of, cites). Each node and edge is associated with a type, and (e.g., paper, cited-by). Each item type has a number of associated attributes (e.g., topic, year). Consequently, each object and link is associated with a set of attribute values determined by their type, and . A PRM represents a joint distribution over the values of the attributes in the data graph,
The network is represented by the product of conditional probability distributions (CPD) of one node given its parents. There are a few things need to be clarified:
Since RDN is a cyclical graph, the product of CPD does not necessarily be the joint distribution, but under some conditions, it is quite close to the joint one.
In practice, the parents of one node is not given exhaustedly, moreover, we use query from relational database to return a local network for each node and condition on them.
Many machine learning algorithms can reveal the dependency of the variables, i.e. from the local network queried, to select the nodes that are parents of one node.
2.1. RDN learning
The pseudo-likelihood for data graph is computed as a product over the item types , the attributes of that type , and the items of that type :
here may not be an explicit set of parameters, but implicit structure like tree. Therefore, we can maximize CPD for every node to maximize pseudo-likelihood:
using some learners like Relational Bayesian Classifiers as well as Relational Probability Trees. After we maximize the pseudo-likelihood, we also learn the dependency among the nodes, like model graph in Figure 1(b).
2.2. RDN inference
For some unknown nodes, we can use Gibbs sampling to make the inference. We first assign all unknown nodes a prior probability and draw from this prior distribution. Then, for each unknown node, we can randomly draw one sample from its CPD we have learned above. The empirical marginal and joint distribution can be calculated from the samples we draw from the Gibbs sampler.
