Neural Architecture Search
- Neural architecture search: A survey. (Elsken et al., 2019 JMLR)
- A Comprehensive Survey of Neural Architecture Search- Challenges and Solutions
1. Search Space
chain-structured neural networks: sequence of n layers
multi-branch networks: incorporates modern design elements, known from hand-crafted architectures, such as skip connections
Search for cells or blocks, then the final architecture is then built by stacking these cells in a predefined manner (or macro-structure search)
Learning Transferable Architectures for Scalable Image Recognition. (Zoph et al., 2018 CVPR )
- Use a controller RNN to predicts the rest of the structure of the convolutional cell, given two initial hidden states
The predictions of the controller for each cell are grouped into B blocks, where each block has 5 prediction steps made by 5 distinct softmax classifiers corresponding to discrete choices of the elements of a block

The controller RNN was trained using Proximal Policy Optimization (PPO).
2. Search Strategy
Random search
Bayesian optimization
Evolutionary methods
Reinforcement learning
Neural architecture search with reinforcement learning. (Zoph and Le, 2017 ICLR)
Use a controller RNN to predict hyperparameters of the network layers
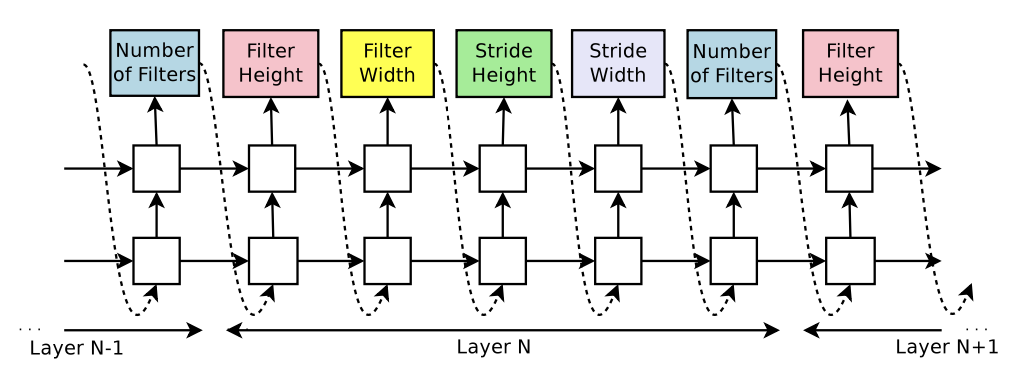
Use reinforcement learning to train, ask our controller to maximize its expected reward. Use REINFORCE rule.

Can add skip connections and attention structure.
Gradient-based methods
DARTS- Differentiable Architecture Search. (Liu et al., 2019 ICLR)
To make the search space continuous, we can relax the categorical choice of a particular operation to a softmax over all possible operations:
This implies a bilevel optimization problem with as the upper-level architecture variable and as the lower-level network parameters:
Consider a simple approximation scheme as follows:
Applying chain rule to the approximate architecture gradient yields and the Hessian can be approximated using finite difference method:
3. Performance Estimation Strategy
- Lower fidelity estimates: Training time reduced by training for fewer epochs, on subset of data, downscaled models, downscaled data
- Learning curve extrapolation: Training time reduced as performance can be extrapolated after just a few epochs of training.
- Weight inheritance: Instead of training models from scratch, they are warm-started by inheriting weights of, e.g., a parent model.
- One-Shot models/ Weight sharing: Only the one-shot model needs to be trained; its weights are then shared across different architectures that are just subgraphs of the one-shot model.