Feature Interaction
1. Deep & Cross
- Deep & cross network for ad click predictions. (Wang et al., KDD 2017)
- 揭秘 Deep & Cross : 如何自动构造高阶交叉特征
Deep and Cross 结构:
- Deep 层正常DNN
- Cross层做interaction
- 将两部分输出拼接起来再过FC+sigmoid
- Cross 层交叉组合特征,再加上一个residual block
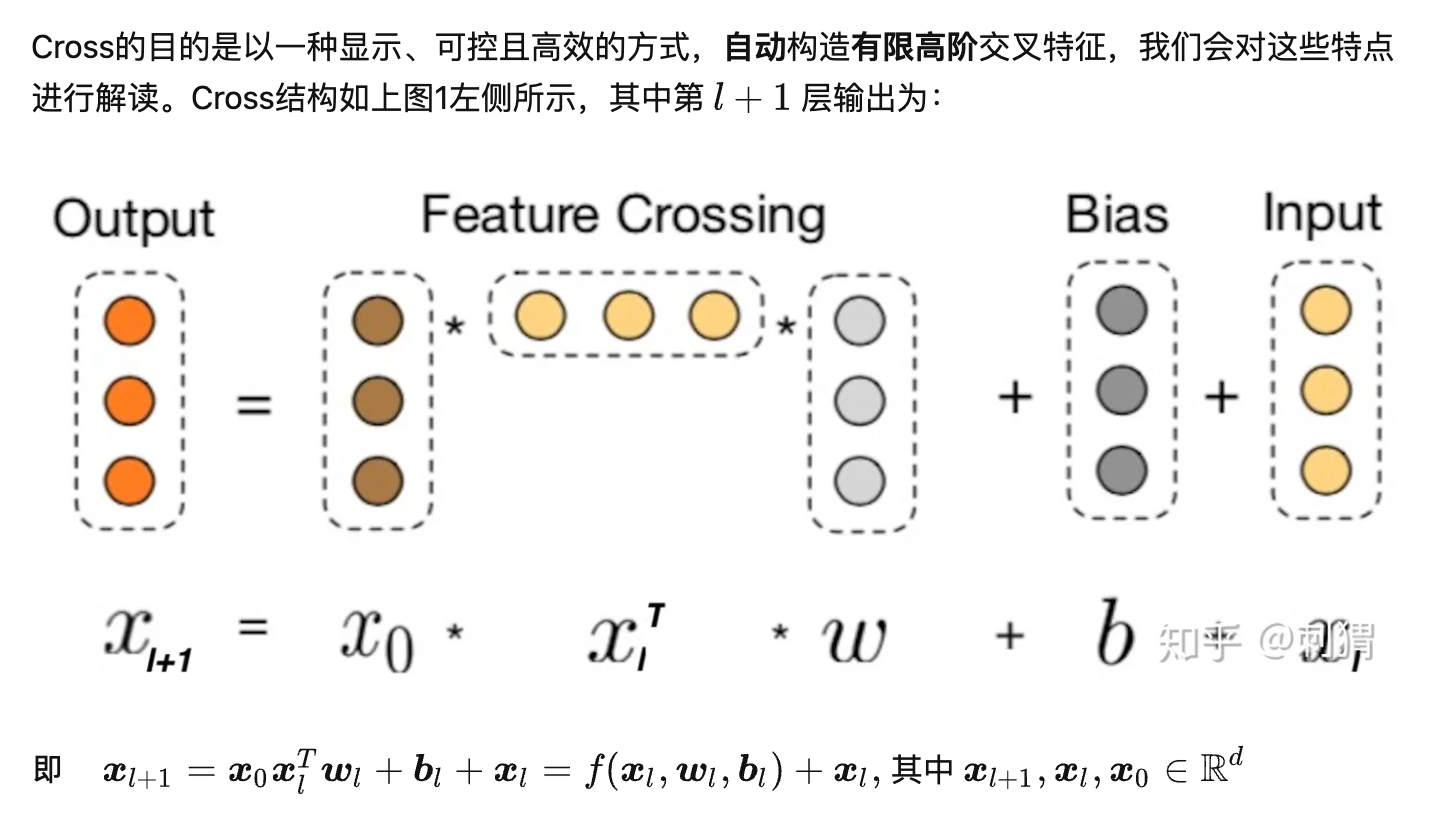
Deep & Cross 特点
- 有限高阶:叉乘阶数由网络深度决定,深度 对应最高 阶的叉乘
- 自动叉乘:Cross输出包含了原始特征从一阶(即本身)到 阶的所有叉乘组合,而模型参数量仅仅随输入维度成线性增长:
- 参数共享:不同叉乘项对应的权重不同,但并非每个叉乘组合对应独立的权重(指数数量级), 通过参数共享,Cross有效降低了参数量。此外,参数共享还使得模型有更强的泛化性和鲁棒性。例如,如果独立训练权重,当训练集中 这个叉乘特征没有出现 ,对应权重肯定是零,而参数共享则不会,类似地,数据集中的一些噪声可以由大部分正常样本来纠正权重参数的学习
2. xDeepFM
- xDeepFM: Combining explicit and implicit feature interactions for recommender systems. (Lian et al., KDD 2018)
- xDeepFM:名副其实的 ”Deep” Factorization Machine
网络结构:
CIN层的输入来自Embedding层,假设有个field,每个field的embedding vector维度为,则输入可表示为矩阵 .
不同于Deep & Cross (DCN) whose input is a vector in , xDeepFM can be seen as a generalized version DCN with vector-wise product instead of bit-wise product.
令 表示第 层的输出, 其中 表示第 层的vector个数, vecor维度始终为 保持和输入层一致。具体地, 第 层每个vector的计算方式为: where and is the -th output vector (weight matrix) in the -th layer, and is the Hadamard product. 当输入维度 的时候,xDeepFM化简成DCN。
另一点与DCN的不同是,xDeepFM不拟合残差,因此第层只能表示阶组合特征,而DCN表示从1到阶全部组合特征。相应地,DCN在最后一层输出层输出结果,而xDeepFM在每层都输出中间结果。
3. Auto-Int
- AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks (Song et al., CIKM 2019)
- AutoInt:基于Multi-Head Self-Attention构造高阶特征
模型结构:
- 类似xDeepFM,input feature 分成 个field,每个过一个embedding 层得到一个嵌入向量 .
- Interacting Layer 进行 multi-head self-attention, 在每个head上,对 进行一次 self-attention. 每个 Attention head 都对应着三个转换矩阵: . 对于第 个 Attention head, 当第 个嵌入向量 作为query时, 其对应输出 为:
对第个嵌入 , 作者简单拼接它在 个Attention head的输出, 然后引入标准的残差连接作为其最终输出 :
以上方法得到第 个嵌入的对其他嵌入的二阶特征组合,以此类推可以叠加多个这样的层,构造更高阶的组合特征。当然,也可以在旁边搭个Deep层一起合作。
最终的预测输出为:
4. S^3-Rec
模仿BERT的预训练模式,通过自监督学习构造更好的embedding表达。